Bayesian Whitelisting: Finding the Good Mail Among the Spam
The biggest challenge with spam filtering is reducing false
positives--that is, finding the good mail among the spam. Even the
best spam filters occasionally mistake legitimate e-mail for spam. For
example, in some recent
tests, bogofilter
processed 18,000 e-mails with only 34 false positives. Unfortunately,
several of these false positives were urgent e-mails from former
clients. This unpleasant mistake wasn't necessary--the most important
of these false positives could have been avoided with an automatic
whitelisting system.
Not All False Positives are Equally Bad
False positives are bad, but some are much worse than others. Mistaking a random stranger's legitimate e-mail for spam is bad, but mistaking your boss' important memo for spam is a disaster. In addition to your boss, you'll also need to be careful with your family members, your partner companies, your government sponsors, your business clients, and your car insurance company.
Spam Assassin and Auto-Whitelisting
The popular (and highly effective) SpamAssassin package has a clever solution to this problem: an automatic whitelist. After SpamAssassin filters each e-mail, it combines that e-mail's "spam score" with the average of all previous e-mails from the same person. Over time, SpamAssassin therefore learns the addresses of your friends and colleagues, and begins filtering their messages less aggressively. The result: a drop in the number of false positives.
Unfortunately, because SpamAssassin's auto-whitelist is based on averaging spam scores, it will only work for filtering systems which use spam scores. Other popular spam filtering systems, however, use naive Bayesian probailities, k-nearest neighbor algorithms and latent semantic analysis. For these systems, we need another kind of automatic whitelist.
What Your Spam Filter Knows That the Spammers Don't
Your spam filter has some advantages over the spammers--it sees all the e-mail addresses (and domains) in your incoming mail, and it has a pretty good idea which messages are spam and which aren't. How can your spam filter exploit this knowledge to build a whitelist? The simplest approach would be to sort e-mail addresses (and domains) into "spammer" and "non-spammer" categories, and whitelist anybody in the "non-spammer" category. But how should we deal with the borderline cases? And while we're at it, why don't we look at the "To" and "CC" addresses as well?
Properties of a Good Whitelist
Paul Graham described the properties of a good spam filter: it should catch as much spam as possible without catching any significant amount of good e-mail. I propose that the properties of a good whitelist are exactly the opposite: it should accept as much good e-mail as possible without accepting any significant amount of spam. Furthermore, a good whitelist should accept virtually all e-mail from family members, clients, sponsors, and other people with whom you regularly correspond.
Bayesian Whitelisting
Paul Graham wrote an excellent essay on Bayesian spam filtering. I decided to turn this technique around and apply it to whitelisting. Instead of processing message bodies, I only look at e-mail addresses.
We can extract the e-mail addresses as follows, using the Python
rfc822 module:
def message_addresses(message):
addrs = message.getaddrlist("from")
addrs += message.getaddrlist("reply-to")
addrs += message.getaddrlist("sender")
addrs += message.getaddrlist("x-beenthere")
addrs += message.getaddrlist("x-mailinglist")
# Extract the recipient addresses (or use "MISSING_TO" if there
# aren't any obvious recipients--but this may not actually be
# useful in practice).
to_addrs = message.getaddrlist("to")
to_addrs += message.getaddrlist("cc")
to_addrs += message.getaddrlist("bcc")
if len(to_addrs) == 0:
to_addrs = [("No recipient address", "MISSING_TO")]
addrs += to_addrs
# Convert to lower-case, and remove recipient's address.
lc_addrs = [p[1].lower() for p in addrs]
lc_self_addrs = [a.lower() for a in OWN_ADDRESSES]
return [a for a in lc_addrs if (not a in lc_self_addrs)]
I ignore all distinctions between 'To' and 'From' addresses, because spammers routinely switch these headers around to trick filters. I also filter out the user's own addresses, which tend not to be helpful in identifying spam. I do, however, look at 'CC' addresses, because these tend to be highly informative.
Training the Filter
Training the filter is very simple. (In this example, I use Eric Raymond's term "ham" to refer to non-spam e-mail.)
def train_on_addresses(msg_type, addrs):
# Figure out which databases to use.
if msg_type == HAM:
addr_db = HAM_ADDRS
host_db = HAM_HOSTS
elif msg_type == SPAM:
addr_db = SPAM_ADDRS
host_db = SPAM_HOSTS
else:
raise "Invalid message type"
# Update our databases.
for addr in addrs:
db_increment(COUNTS, addr_db)
db_increment(addr_db, addr)
host = address_host(addr)
if host is not None:
db_increment(COUNTS, host_db)
db_increment(host_db, host)
Notice that we keep track of both addresses and hosts. This will be
useful when we start seeing addresses of the form
unknown-vp@consultingclient.com and
offer-192@majorspamhaus.com.
Examining a Message
To decide whether we should whitelist a message, we perform a naive Bayesian analysis of the e-mail addresses it contains. This isn't statistically rigorous--it assumes that all the variables are independent, and that we can correctly estimate spam propabilities using our training data--but it's not too far off the mark.
# Anything with a spam probability less than CUTOFF
# will be whitelisted. Any number > 0.01 and < 0.50 would work
# fairly well on current spam.
CUTOFF = 0.05
# Look up a key in one of our databases
def query(ham_db, spam_db, key):
hamness = 1.0 * db_lookup(ham_db, key) / db_lookup(COUNTS, ham_db)
spamness = 1.0 * db_lookup(spam_db, key) / db_lookup(COUNTS, spam_db)
if hamness + spamness != 0:
return spamness / (hamness + spamness)
else:
return None
# Use Paul Graham's trick to clamp a probability between
# 0.99 and 0.01, preventing division-by-zero errors later.
def clamp(prob):
if prob is None:
return None
else:
return max(0.01, min(0.99, prob))
# Calculate the probability that a message is spam.
def query_message(message):
addrs = message_addresses(message)
extra_hosts = []
# Calculate the probability using only known addresses.
prob = 0.5
inv_prob = 0.5
for addr in addrs:
addr_prob = clamp(query_address(addr))
if addr_prob is not None:
prob *= addr_prob
inv_prob *= (1 - addr_prob)
else:
# If we don't know the address, remember the host.
host = address_host(addr)
if host is not None and not (host in extra_hosts):
extra_hosts += [host]
# If we can't whitelist the message yet, look at hosts.
if (prob / (prob + inv_prob)) > CUTOFF:
for host in extra_hosts:
host_prob = clamp(query_host(host))
if host_prob is not None:
prob *= host_prob
inv_prob *= (1 - host_prob)
# Return our final score.
return prob / (prob + inv_prob)
Note that we're very careful about how we handle hostnames. We don't even look at them unless the other evidence is inconclusive (to avoid penalizing otherwise good messages which CC a random Hotmail account), and we only consider each hostname once, no matter how many times it appears.
Testing the Whitelist
To test the whitelist, I used the files NONSPAM.TRAIN, SPAM.TRAIN,
NONSPAM.CONTROL and SPAM.CONTROL from my previous tests. These
files contain a total of approximately 5,600 messages, split evenly
between the four categories. After training on the NONSPAM.TRAIN and
SPAM.TRAIN files (with one modification to simulate an attack), I
plotted the results of query_message for NONSPAM.CONTROL and
SPAM.CONTROL using Python's excellent biggles module.
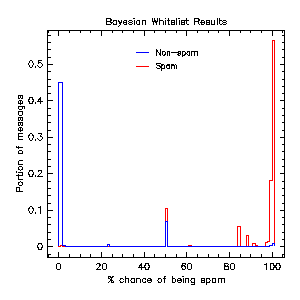
Bayesisan whitelisting results.
The clump between 0% and 1% represents unamibiguously good messages. The clump at 50% represents messages with no evidence one way or the other, and the clump at 100% represents messages which are almost certainly spam (I'm surprised that so many spammers have predictable e-mail addresses, actually). The messages scattered elsewhere typically involve ambiguous evidence or unknown accounts at large ISPs and webmail providers.
(This histogram suggests that we could actually use a simpler technique than naive Bayesian analysis, at least in this case. Naive Bayesian analysis tends be robust, however, and will learn to ignore any data that spammers figure out how to forge.)
Numerical Results
In this example, the filter accidentally whitelisted 4 spams (0.003%), two of them from a previously trustworthy ISP in Italy; and failed to whitelist 122 non-spam messages (8.7%), mostly from senders who didn't appear in the training set. Additionally, the filter knows that specific Hotmail addresses are trustworthy (0% chance of being spam), but that previously unknown Hotmail addresses are not (84% chance of being spam). The filter has also whitelisted the domains of several former consulting clients, plus the agency which funds my current employer.
Fooling the Whitelist
As mentioned above, I made one modification to the training data to simulate an attack on this filter--I assumed that most spams were CC'd to a random ficticious address at my employer's domain. This simulates a widespread attempt by all spammers to subvert this filter by including at least one "credible" address per message. This has little effect on the filter: it simply learns that my employer's domain is a worthless indicator of spam status.
This shows two things: The whitelist does not need to rely on my employer's domain to get good results, and naive Bayesian analysis learns to ignore any sufficiently widespread attack.
Another possible problem may occur for users who receive lots of legitimate e-mail from a large service (such as Hotmail) or from a high-traffic mailing list without spam controls. If more than 95% of the e-mail mentioning a given domain or list is legitimate, then the whitelist will begin to accept some spam. However, if this problem actually occurs in practice, the effects could be reduced by lowering CUTOFF to something around 2%, or by calculating host probabilities from good and bad addresses instead of from good and bad messages.
Conclusion
Bayesian whitelisting is a simple, efficient technique for reducing false positives in an otherwise reliable spam filter. In this experiment, it whitelisted 92.3% of the legitimate e-mail, and only 0.003% of the spam. Because Bayesian whitelisting focuses on the e-mail addresses and domains of known "good" senders, it's particularly effective at identifying important e-mails which might otherwise be blocked by an overly-eager spam filter.
Combined with a highly-selective spam filter, Bayesian whitelisting should reduce false positives by a noticeable margin without significantly increasing the false negative rate.
Call For Help
If you'd like to experiment with Bayesian whitelisting, please
e-mail me for a copy of bwl.py. I'm especially interested in
seeing copies of the biggles plot (above) for mail feeds other than my
own. I'll post any updates on this page.
Want to contact me about this article? Or if you're looking for something else to read, here's a list of popular posts.